Live Demo
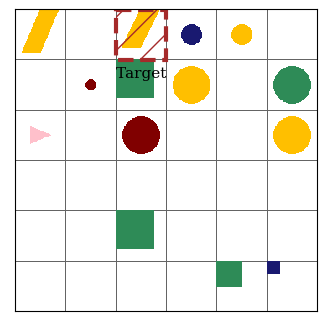
Command: x
Command pattern: x
Action sequence: x
ReaSCAN: Compositional Reasoning in Language Grounding
ReaSCAN is a synthetic navigation task that requires models to reason about surroundings over syntactically difficult languages.
Release Notes
- 11/28/2021: We release newer version of non-generalization testing sets for different command patterns as ReaSCAN-v1.1.zip.
- 07/29/2021: Our paper is accepted to NeurIPS2021 with OpenReview.
- 06/17/2021: We update model performance results by fixing known issues. We include more compositional splits as well.
- 06/07/2021: We submit our preprint to NeurIPS2021.
Getting Started
Step 1: Download ReaSCAN
We generated ReaSCAN using our pipeline with fixed random seeds. You can reproduce the version of ReaSCAN we use in the paper by running the pipeline. Additionally, we also update the version we use to a online folder where you can directly download and use as-it-is. Note that, the dataset files are really large. It may take a while to download them.
Our generated data is in ReaSCAN-v1.1.zip (Note that we updated our files to hotfix some of existing issues on 06/16/2021. We also included newer non-generalization testing sets on 11/28/2021), which is saved in a shared drive. The dataset consists subsets generated for different patterns (P1: Simple (similar to gSCAN), P2: 1-relative-clause, P3: 2-relative-clauses, P4: 3-relative-clauses) and different compositional splits (see our paper for details about each split).
Random splits that can be used for training your models,
ReaSCAN-compositional: ReaSCAN all commands, containing train, dev and test sets.ReaSCAN-compositional-p1: ReaSCAN Simple set, containing train, dev and test sets.ReaSCAN-compositional-p2: ReaSCAN 1-relative-clause set, containing train, dev and test sets.ReaSCAN-compositional-p3: ReaSCAN 2-relative-clauses set, containing train, dev and test sets.ReaSCAN-compositional-p1-test: ReaSCAN Simple set, containing test set only. Model performance is reported in the paper.ReaSCAN-compositional-p2-test: ReaSCAN 1-relative-clause set, containing test set only. Model performance is reported in the paper.ReaSCAN-compositional-p3-test: ReaSCAN 2-relative-clauses set, containing test set only. Model performance is reported in the paper.ReaSCAN-compositional-p1-test-updated: UPDATED ReaSCAN Simple set, containing test set only. Model performance is NOT reported in the paper.ReaSCAN-compositional-p2-test-updated: UPDATED ReaSCAN 1-relative-clause set, containing test set only. Model performance is NOT reported in the paper.ReaSCAN-compositional-p3-test-updated: UPDATED ReaSCAN 2-relative-clauses set, containing test set only. Model performance is NOT reported in the paper.ReaSCAN-compositional-p3-rd: ReaSCAN 2-relative-clauses set with random distractors, containing train, dev and test sets.
Compositional splits that are designed to be zero-shot testing splits,
ReaSCAN-compositional-a1: ReaSCAN A1 (novel color modifier) compositional split, containing test set only.ReaSCAN-compositional-a2: ReaSCAN A2 (novel color attribute) compositional split, containing test set only.ReaSCAN-compositional-a3: ReaSCAN A3 (novel size modifier) compositional split, containing test set only.ReaSCAN-compositional-b1: ReaSCAN B1 (novel co-occurence of objects) compositional split, containing test set only.ReaSCAN-compositional-b2: ReaSCAN B2 (novel co-occurence of relations) compositional split, containing test set only.ReaSCAN-compositional-c1: ReaSCAN C1 (novel conjunctive clause length) compositional split, containing test set only.ReaSCAN-compositional-c2: ReaSCAN C2 (novel relative clauses) compositional split, containing test set only.
You can also generate your own compositional splits by modifying couple lines in code/dataset/generate_ReaSCAN_splits.ipynb.
Step 2: Loading ReaSCAN
Once you generate the dataset .txt file (in json format), you can simply load any dataset as,
import json
path_to_data = "data-compositional-splits.txt"
logger.info(f"Reading dataset from file: {p1_path_to_data}...")
data_json = json.load(open(path_to_data, "r"))
print(data_json["examples"].keys())
Leaderboard
This section contains the leaderboard for scores obtained by papers on ReaSCAN. To add scores please consider a pull request.
| M-LSTM [1] | GCN-LSTM [2] | |
|---|---|---|
| Random | 79.04 +- 1.24 | 98.96 +- 0.59 |
| A1: novel color modifier | 50.36 +- 4.03 | 92.25 +- 0.77 |
| A2: novel color attribute | 14.65 +- 0.55 | 42.05 +- 4.55 |
| A3: novel size modifier | 50.98 +- 3.69 | 87.46 +- 2.22 |
| B1: novel co-occurrence of objects | 52.17 +- 1.63 | 69.74 +- 0.30 |
| B2: novel co-occurrence of relations | 39.41 +- 1.53 | 52.80 +- 2.75 |
| C1: novel conjunctive clause length | 49.68 +- 2.73 | 57.01 +- 7.99 |
| C2: novel relative clauses | 25.74 +- 1.36 | 22.07 +- 2.66 |
| Avg ReaSCAN Score | 40.43 | 60.48 |
[1] Laura Ruis, Jacob Andreas, Marco Baroni, Diane Bouchacourt, Brenden M. Lake. 2020. “A Benchmark for Systematic Generalization in Grounded Language Understanding “ in NeurIPS 2020.
[2] Tong Gao, Qi Huang, Raymond J. Mooney. 2020. “Systematic Generalization on gSCAN with Language Conditioned Embedding” in AACL-IJCNLP 2020.
Caveats: The random split here is the same one used in our paper. Numbers may change with updated random split.
Usage
If you are using ReaSCAN, please consider to cite our paper as,
@article{wu-etal-2021-reascan,
title={Rea{SCAN}: Compositional Reasoning in Language Grounding},
author={Wu, Zhengxuan and Kreiss, Elisa and Ong, Desmond C. and Potts, Christopher},
journal={NeurIPS 2021 Datasets and Benchmarks Track},
url={https://openreview.net/forum?id=Rtquf4Jk0jN},
year={2021}}